
UI/UX in the age of Generative AI
How the best products are approaching UI/UX for generative ai features

GenAI features are rapidly popping up in products across industries, from fintech (Ramp, Brex) to design (Adobe, Figma). Nearly every day, somebody ships a new AI feature to much fanfare on X.
Yet while some GenAI features have taken off (Cursor Tab, Claude Artifacts), most have gone to the growing graveyard of flashy but forgotten novelties. Many products go immensely viral, driving thousands of signups. Yet most users don’t come back, usually either because they were disappointed or because the product wasn’t truly useful.
Why consider my opinion? I’ve tried pretty much every AI feature out there. I also code.
I believe that the discrepancy in outcomes arises, in part, from a failure to understand how GenAI UI/UX differs from previous paradigms.
In this article, I’ll discuss four areas where GenAI features differ from pre-GenAI features. I’ll also give examples of GenAI features that get each right. Only GenAI features that require active user interaction will be considered. For example, this excludes Amazon’s use of LLMs to summarize product reviews.
GenAI features are:
Probabilistic (outputs are unpredictable and need to be fixed)
Address through: editability, DSLs, constraints, templates
Delayed (users have to wait)
Address through: informative progress indicators, proactive async operations
Underdetermined (prompts are not specific enough)
Address through: request refinement, prompt enhancement
Conversational (typing/natural language is clunky)
Address through: non-chat elements, shared context and workspace
GenAI is Probabilistic
We’ll start by talking about image models and then move onto LLMs.
Frontier models are generally reliable yet also unpredictable when it matters. User don’t get to control what comes out exactly.
Dealing with Image Models
Take Midjourney, one of the most popular image model companies. An analysis of 3.5M Midjourney prompts reveals that one of the most common use cases is logo generation.
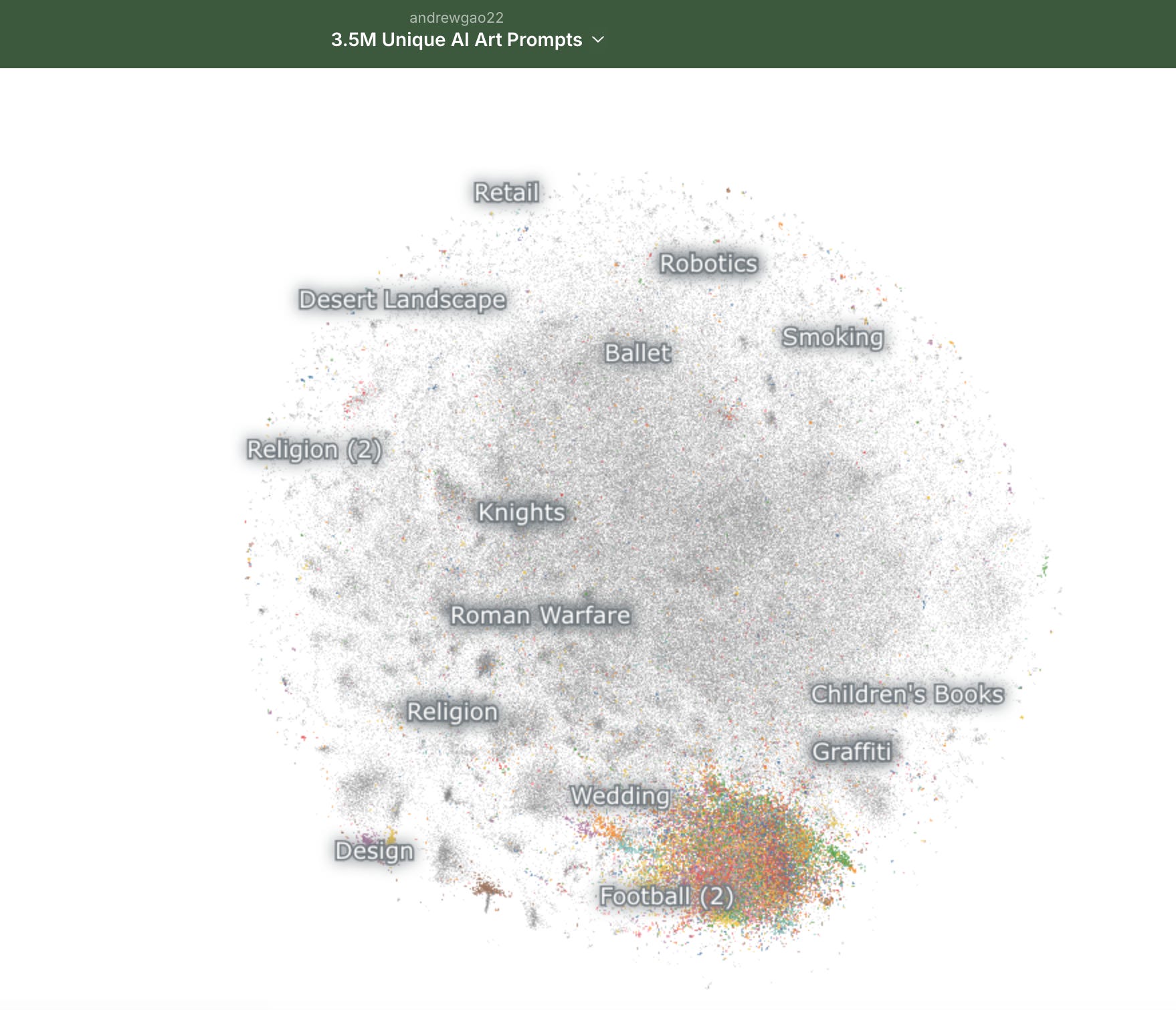
It’s easy to understand why logo generation is so popular. Hiring a designer is (relatively) expensive and also takes time.
Yet, we arrive at a pitfall. Logos have to be perfect. There are so many tiny ways an image generator can mess up. For example, text is notoriously hard (although we are making progress). Or, the background might not be white (and then when you ask to regenerate, you might get a white background but a different logo!).
Most often, there are a couple small details that are messed up that end up disqualifying an “almost-good-enough” logo. For example, the below logo looks nice but has mistakes if you look closely—and thus can’t be used in production.

There are several ways to address this:
Generate a ton of images
Midjourney does this by default, giving you four images each time. It costs them 4x as much, but also serves as a valuable data flywheel.
Pros: if you make enough, some will be better; you can use user preference as fine-tuning data
Cons: compute costs; users have to spend time sifting through options; doesn’t actually solve the issue of tiny mistakes

Selective Regeneration
Adobe Firefly lets users generate an entire image, and then re-generate selected portions of the image. This enables more precise control.

Editability
This is where fleshed-out platforms like PhotoShop and Canva have the edge. Image generation models make mistakes, so let the user correct them manually. The con here is that users have to learn how to use the platform.
Dealing with LLMs
LLMs are a little nicer than image models because text is very easy to edit. Unlike images where users need to edit pixels (tiny, lots of colors), everyone knows how to rewrite.
Currently, LLMs are used in three main ways (in order of complexity):
Vanilla text/code generation (Jasper, ChatGPT, Notion AI, Cursor, Copilot)
Object generation (Claude artifacts, Notion Flowcharts, Gatekeep Labs)
Object referring to things like animations, charts, Manim videos, Figma designs, etc.
Workflow automation (Devin, Ramp Agent)
Taking advantage of the reasoning ability of LLMs to take actions for the user
The challenge here, like with image models, is that LLMs are probabilistic so your software has to account for a lot of possibilities. This is especially challenging when LLMs are being used to take actions, not just generate something.
DSLs/Constraints/Templates (for LLMs)
DSL = Domain Specific Language, i.e. Excel formulas, RegEx, SQL, Manim, Lean
The general strategy is to constrain what LLMs are allowed to do, increasing reliability and making it easier to fine-tune. Ideally, the DSL is easily verifiable, i.e. you can compile the LLM’s output and see if there’s an error, in which case you send it back for debugging.
For example, if you wanted to have an LLM generate 3Blue1Brown-style Manim videos, you would not just prompt the LLM to “generate an animation of {X}”. You would want to provide detailed guidelines of how it should approach the problem. In this case, you would likely want to instruct it to use Manim, include some Manim rules and examples in the prompt, and perhaps even give it access to RAG over Manim code examples.
On that note, using templates is another good strategy, although it does limit the diversity of outputs. Figma AI and Vercel V0 are good examples. Figma provides its LLM with a set of design libraries, which contain “building blocks” that work well together. When the LLM generates a design, it references these design libraries a.k.a. templates to base its design off of. This is important because LLMs generally struggle with positioning and spacing (they are pretty bad at fixing CSS). So, having a reliable set of templates that are properly configured is useful.

As for Vercel V0, I’m not exactly sure of the underlying mechanics (and they’ve updated the product tremendously since last fall). I can say that they use shadcn components, which are akin to the Figma building blocks. By limiting the output space of the LLM to code that uses shadcn, Vercel is able to increase reliability of V0’s outputs. It’s easier to fine-tune and improve when you are focused on shadcn and don’t have to worry about your LLM generating websites in any language or framework.

State Machines (for workflow automation)
In the case of workflow automation, representing your AI agent as a state machine can be very powerful. LangChain’s LangGraph is good for this (disclaimer: I was in their Hacker in Residence program).
The state machine abstraction is helpful because it makes it easier to prevent your LLM from coming up with a illegal/disallowed workflow where it tries to take actions it shouldn’t or actions that don’t exist.
GenAI Outputs are Delayed
People are used to instant gratification. In most software applications, you can click a button and expect the action to take place instantly. But with many GenAI features, you have to wait because it takes time to compute the answer.
Of course there are exceptions. It takes time to export videos from iMovie. It takes time for Amazon to process your payment.
I suppose I would clarify my statement by saying this:
Most Non-GenAI features are fast, but some are slow. GenAI features are always slow
I don’t have a very novel insight to share on this topic and I hate saying obvious things. I think the progress bar works well for GenAI features. And, streaming responses when possible is obviously very important: users can read the response well before the last token is generated. ChatGPT without streaming would be agonizingly slow.
I would like to highlight two good examples of products that handle delayed outputs well.
Midjourney
As Midjourney generates your anime profile photo, it shows you the intermediary diffusion steps. You get to see your image as it develops. This gives you something to look at while waiting.
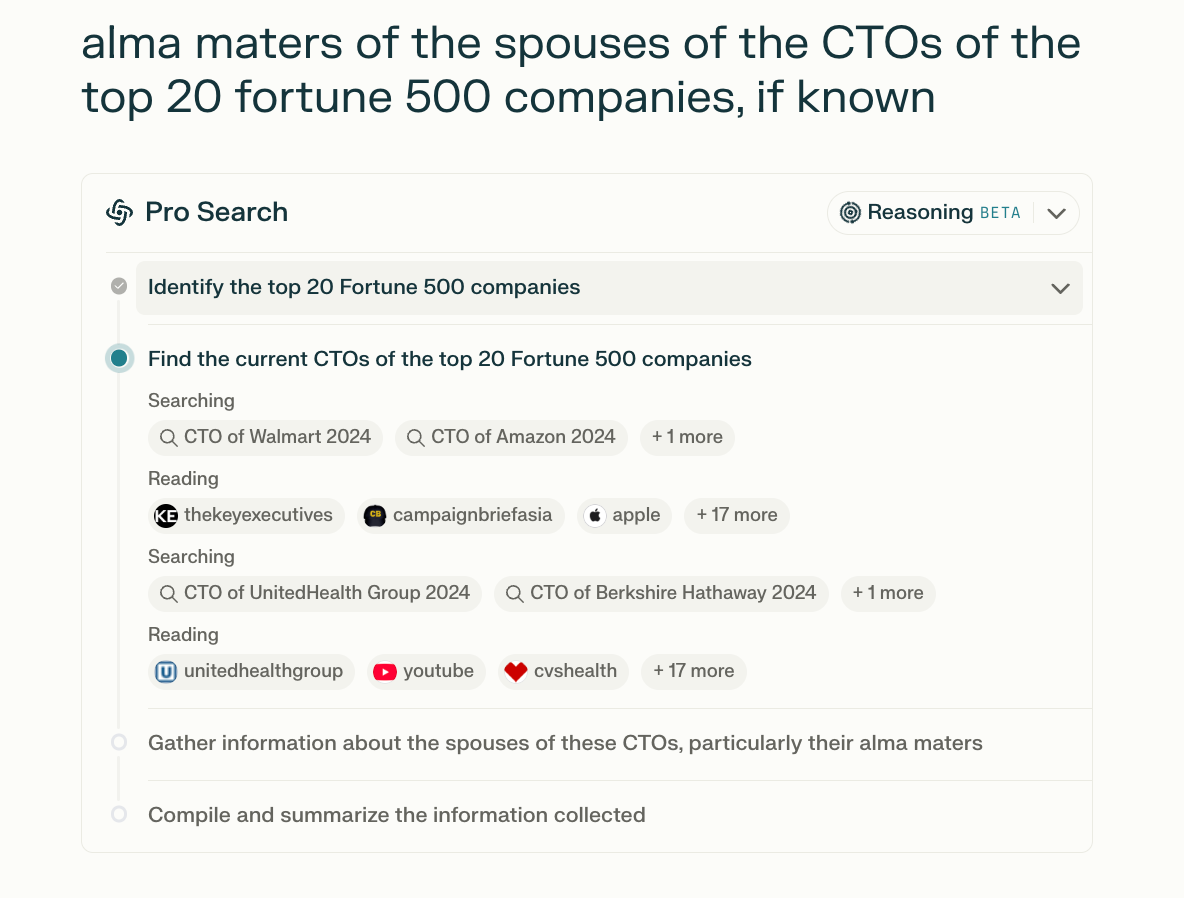
Perplexity
Perplexity would be a terrible user experience if it didn’t have this progress flow. I get to see the steps Perplexity is taking and even visit the sources as I wait. The flow provides observability, granting me confidence and oversight on the output. And again, it gives me something to look at. Imagine if Perplexity didn’t do this and instead just had you looking at a spinning circle for an entire minute while it searched.
Proactive Async Operations
Another way to get around the slowness of GenAI is to do as much as possible before the user needs it.
For example, there is no “Embed codebase” button in Cursor. Cursor automatically embeds (and updates embeddings) code in the background. Similarly, Cursor Tab and Github Copilot are always calculating. When they are finished computing a code completion, they un-intrusively display it to the user.
Filler Audio/Cached Responses
This mostly applies to audio applications like real-time phone agents or ChatGPT Voice. Latency is very important for a realistic human-like experience. You can reduce the perceived latency by playing keyboard clicking sounds or playing pre-generated snippets like “Thanks for letting me know, I’ll look into it right now”.
Outlook
Long-term, we can expect delays to decrease as inference gets faster. Decart is working on speeding up GenAI inference (disclaimer: Sequoia-backed). Nvidia, Apple, Etched, Groq, and many others are working on faster chips. In the near future, GenAI models may run so quickly that the latency drops below 200 milliseconds.
This is especially imminent in the case of voice due to speech2speech models like GPT-4o and Kyutai Moshi.
Prompts are Underdetermined/Not specific enough
Natural language instructions are inherently ambiguous, leading to misalignment between user expectations and AI outputs. - Claude 3.5 Sonnet
Natural language is very convenient but it is also terribly underdetermined/imprecise. If you ask an LLM to “generate a personal website for me”, there are infinite websites it could generate and it also has no instructions or information about you. The output is not going to be great.
I see a lot of people complain about how AI is bad because it was unable to fulfill their coding request. Well, most of the time, if you look at the code, it actually did technically fulfill the request. The person’s prompt was just vague and left a lot of interpretations on the table. Before GenAI, you had to specify exactly what you wanted since you were actually doing things yourself. You were selecting the settings and clicking the buttons.
Aside: historically, a software having more buttons meant that it could do more things. GenAI reverses this trend. You can actually do more stuff with fewer buttons. For example, ChatGPT is an email writer, calculator, songwriter, and coding assistant—and it basically has one button (Send).
One way to address this lack of specificity is request refinement.
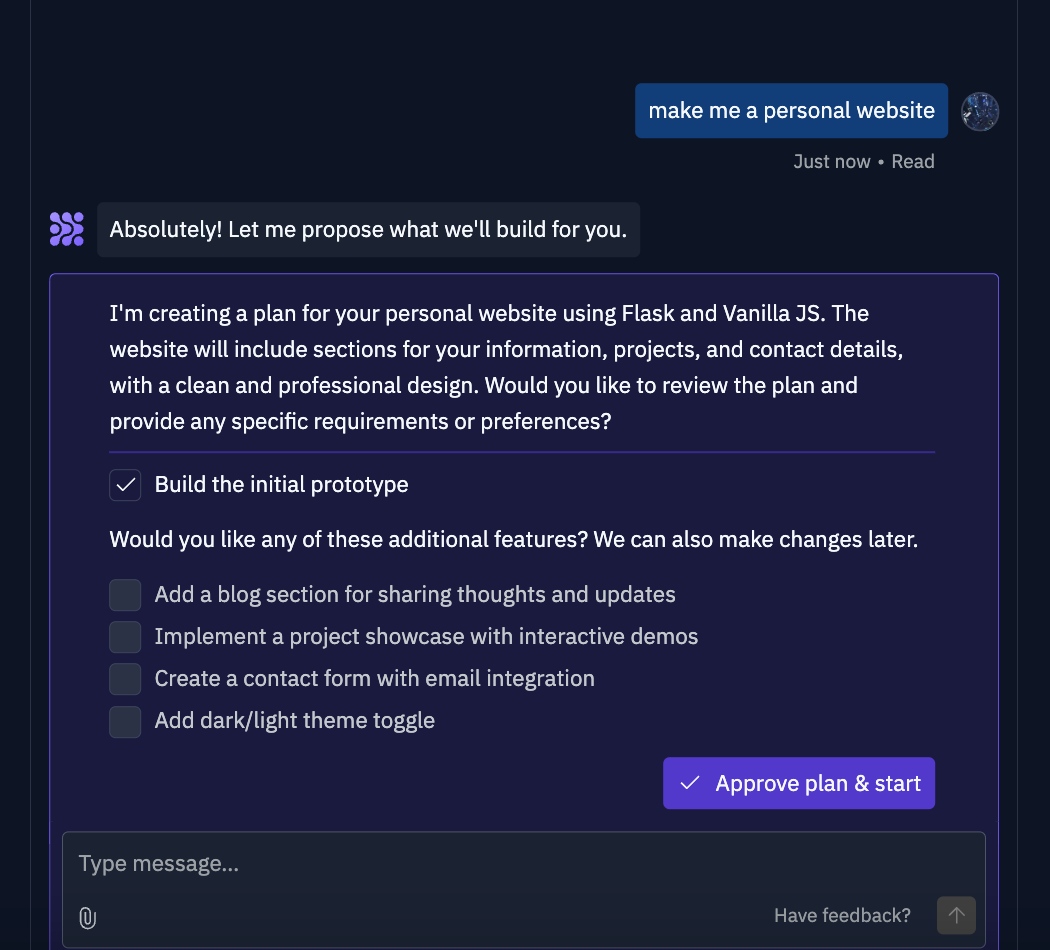
Request Refinement
The idea is simple. Prompt an LLM to keep asking the user questions about their request until a detailed spec is obtained. For example, I asked Replit Agent to code a personal website for me. It comes up with a plan and then asks me to select specific features.
Prompt Enhancement
Another approach is to enhance the user’s prompt with more detail. This is very useful for image models like Midjourney. An image is worth a thousand words (probably more) so any prompt is not going to be able to uniquely determine an output image. A prompt like “cute kitten with green ice cream” could literally lead to billions of unique images.
An example of the prompt enhancing approach is Teleprompter, a simple model I trained to make Midjourney prompts more detailed. A very interesting behavior I observed was that after enhancing, the four images generated by Midjourney were very similar, indicating that the prompt was determined enough that the output space was quite constrained.

Ideally you would present the enhanced prompt(s) to the user so they can approve, edit, or reject it. Keep in mind that the prompt enhancer model is steering the user towards one possibility out of many
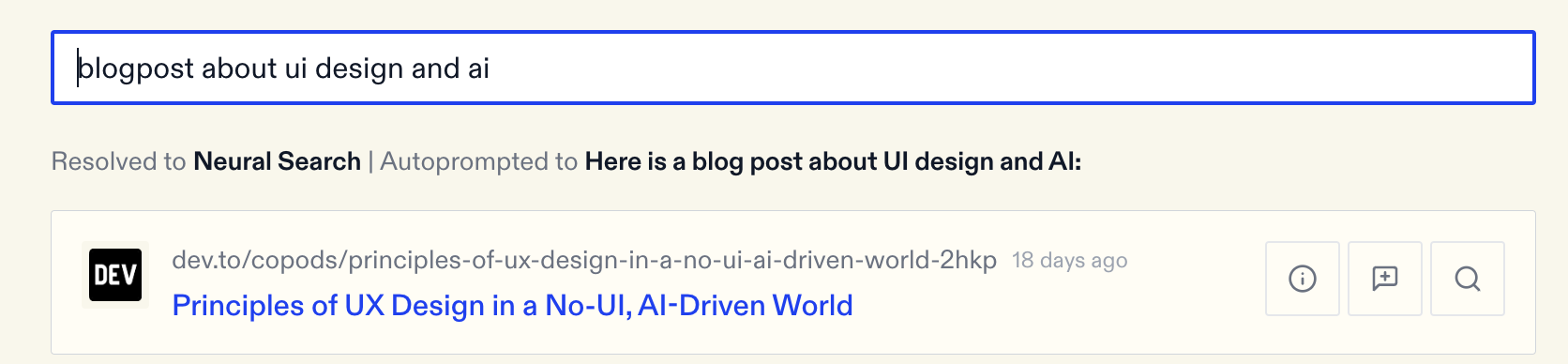
Another example of prompt enhancement is Exa’s Autoprompt feature. Exa is a neural search API that lets you find webpages using embeddings-based search. Because of the way they trained their embedding model, there’s an optimal way to phrase queries which is not what people are used to. In order to reduce friction, they have an Autoprompt feature that converts any query into the ideal format.
Conversational/Chat Interfaces can suck
LLMs have made software conversational, one of the biggest paradigm shifts in the history of computing.
The current local minima of conversational interfaces is the chat interface. Chat interfaces are great in many cases.
Not going to touch on voice interfaces here because they are similar to chat in most ways
Sometimes, chat is awkward. The simplest example of this is that typing is slow. I like Notion’s approach. Yes, you can interact with Notion AI through chat. But you can also quickly trigger common hard-coded AI functions that do a specific task.

Pointing
The biggest issue with chat-only interfaces is that for most modalities, it is hard to point out to the AI what you care about. In the case of Adobe Firefly, it would be impossible to specify the exact areas of an image that you would want to edit through a natural language prompt. Similarly, with Runway (AI video editor), selecting specific frames is much more intuitive than trying to explain which parts of the video should be edited through natural language. And with code, it’s annoying to have to paste code snippets into a chat window.
To address pointing, most good products let the user select things easily, whether that’s a few lines of code or a portion of an image, and then feed that selection to the AI.
Copilot over Chat
Recognizing possible friction, companies are building increasingly collaborative applications that enable users and AIs to interact beyond chat. For example, Cursor and Devin enable back-and-forth interactions between the user and the AI. I like Linus Lee’s characterization of the setup: rich shared context (the AI and the user have access to the same information) and workspace co-inhabitation (the AI can interact with the workspace like the user, i.e. click buttons, change settings). Before, the AI might only have knowledge of whatever the user provided it with in the prompt. Now, the AI fully knows the state of the environment and can consider that when helping users.
Accordingly, we’re seeing a lot of Copilot-esque products that are rebuilding some of the most powerful workspaces with AI at their heart. VSCode → Cursor. PhotoShop → Firefly. Word → Notion. Excel → Paradigm.
Conclusion/TLDR
GenAI features are different in a lot of important ways!
They need special UX consideration due to their unique challenges. Their outputs are unpredictable and often need editing, users have to wait for responses, natural language inputs are frequently too vague, and chat interfaces alone can be clunky. The most successful implementations address these by making outputs editable, showing clear progress indicators, refining unclear requests, and moving beyond pure chat to allow direct interaction like pointing and selecting. Products that account for these differences tend to retain users better than those that simply bolt on AI features.
Summary written by Claude 3.5 Sonnet
Get in touch
Andrew Gao: https://x.com/itsandrewgao / gaodrew [at] stanford (dot) EDU
Related reading:
Footnote on personalization
LLMs are also exciting for UX because they can dynamically adjust software to be personalized to each user. They can also remember information about the user like past requests, preferences, and personal information. Managing this memory (indexing and retrieval) is quite an interesting task!
Thanks for writing this! I've been working on how to mitigate some of these issues and deliver a good experience in an app I've been building. The approach I've ended up taking is to hand off processing to asynchronous background jobs, and to notify the user when data is ready. We're doing things that take 30+ seconds to run, and that may also be queued up behind requests from other users. Fortunately that fits in with expectations many of our users have from other applications they use. It also lets us rerun and refine when outputs don't meet our quality thresholds.
Somewhere in the middle of all this is a fundamental shifting of user expectations and experience. If we can get them to feel like their upfront investment on the input side is nearly always going to yield remarkable results, they'll be ok with some delayed gratification and maybe some iteration on the outputs.